Reading time: 6 min read
Explore the Hidden Power of Sitecore Search’s Document Extractor
How using the request object can help surface reference documents.
Start typing to search...
When you set up a Source within Sitecore Search you can approach the source in a variety of ways. It could be you’re using a sitemap to traverse the site, or maybe you’re using a simple request followed by deep navigation. Either way you approach it, you need to take aspects of each page or item you visit and tag it. You do so using the Document Extractor. You will find the Document Extractors section within the source you are setting up. It can found here:
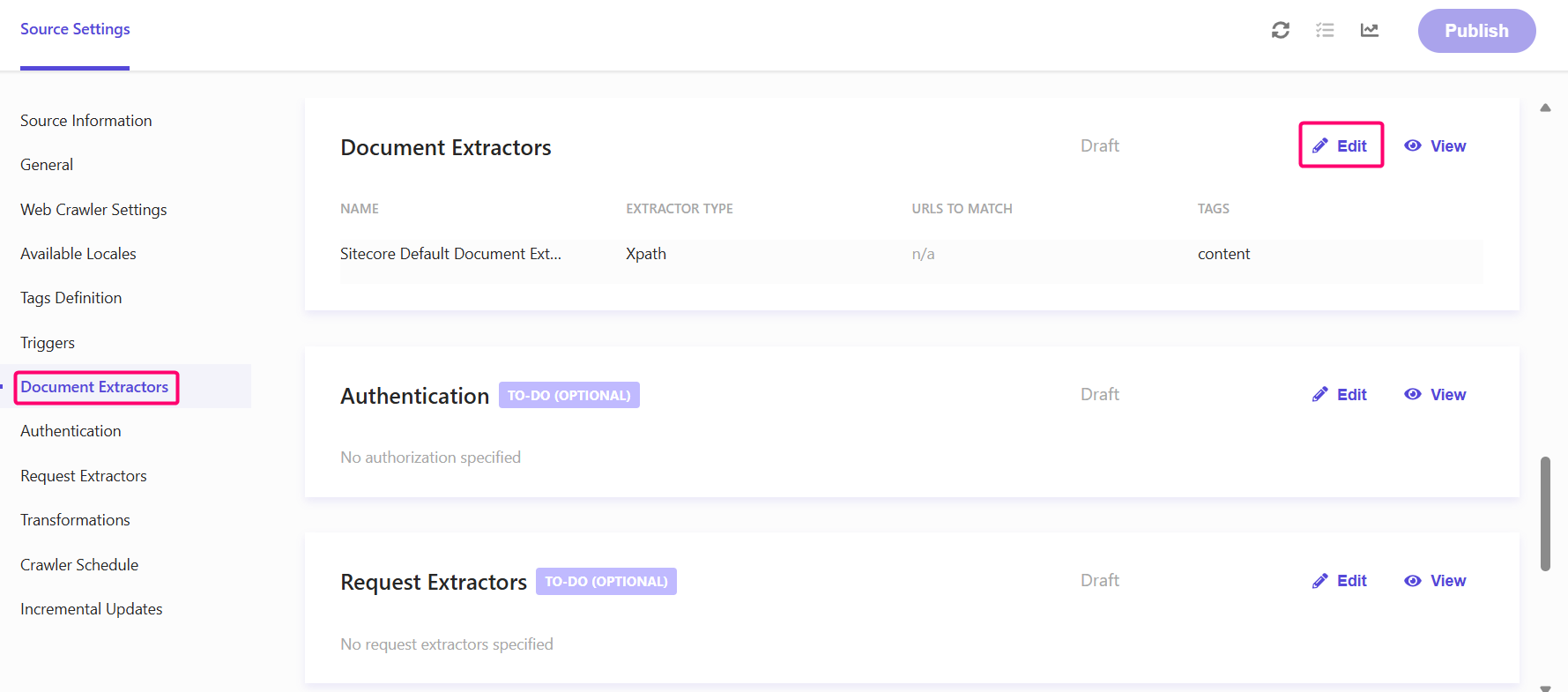
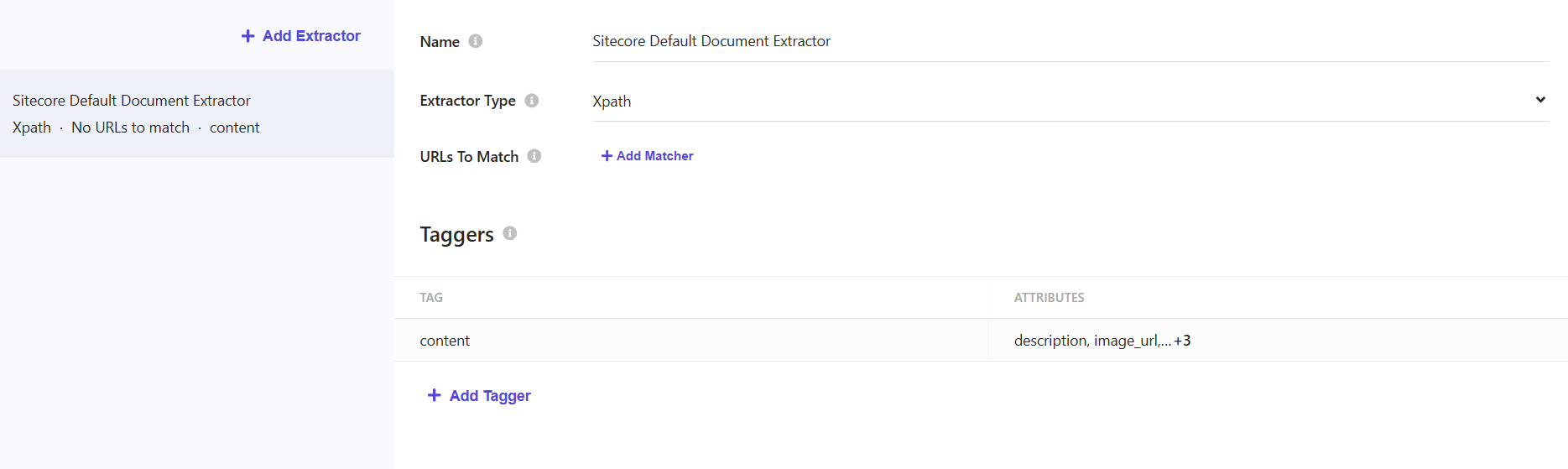
You can setup any number of Document Extractors within a source. Each with its own unique purpose. By default they are set up to utilize Xpath extraction, but you have other options such as CSS and JavaScript.
When you set up an Extractor, you can select the Extractor Type. For the purposes here, we’re going to use the JS option. You can then have it setup to match specific URLs, but I often just use the catch all option. It’s quick, easy. You can do this by setting the Type to Glob Expression and the value to .* as shown below.
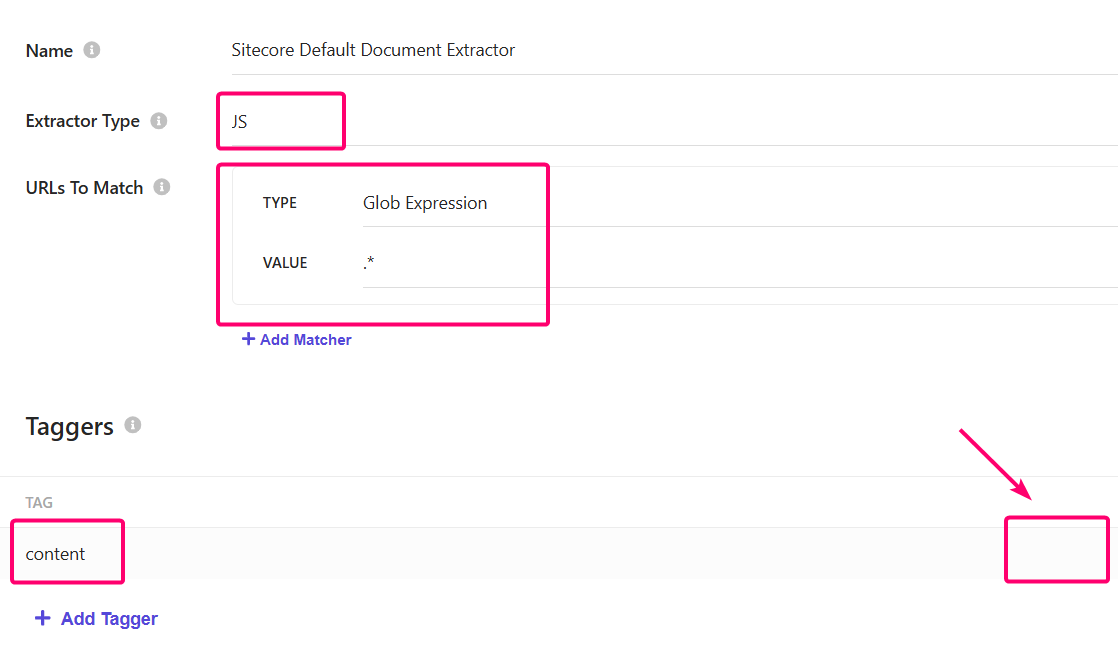
You will then be told to setup a Tagger. Often this is where your metadata is stored and generally this is often left to be content. The box on the right, with the arrow indicates where you will find the Edit pencil. You only see this option, unfortunately, when you hover over the tag.
Think of Taggers as configurations that capture what is in the contents of the page. We are not limited to just the page, as that is what I will show you today.
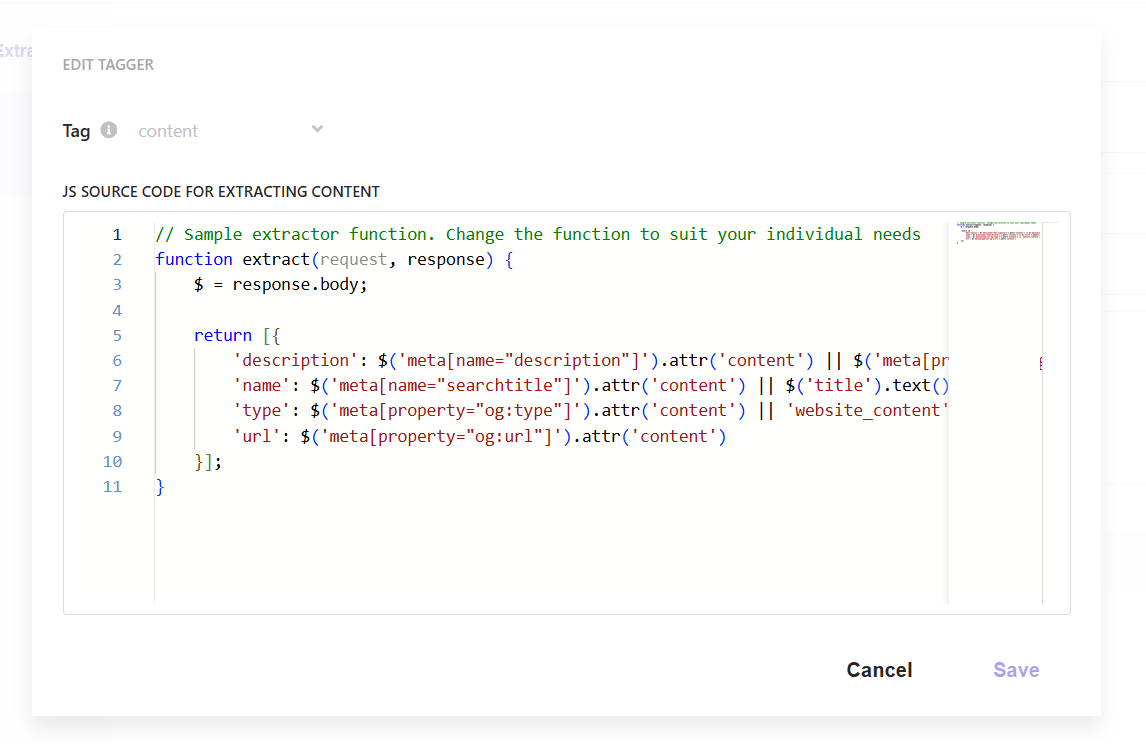
A sample JavaScript source is provided to you to give you an indication what you can do. The JavaScript is based on Cheerio JS. So don’t be thinking it’s JQuery just because of the $.
You can, as the example above shows, assign the metadata properties of a page, or other aspects of the page to various attributes you’ve created in Sitecore Search. There is ample opportunities for fallback if certain values do not exist. So what doesn’t the example show?
What the above example fails to show, is that there is also a request object available to be used. What is in this object you may ask? Literally everything that the referring page got assigned. And not just a single page. The entire depth history of a crawl and all the metadata you’ve assigned to those pages.
So why use this? Where would you use this? Well, the best example might be if you are referring to documents stored outside of your repository. You still want the indexer to crawl them but all you’d have is a link, nothing more. There’s only so much you can infer from that link. Maybe it should be categorized. Maybe it should be secured via a persona such that it doesn’t come back in the search unless a certain criteria is met. Or maybe, if it is a PDF, you want to capture other metadata from within. You can do that.
So what does the request object actually look like? Let’s explore that to understand what information we have at our disposal. You’ll see there is quite a lot. In particular you should notice the details found under context.parent.document and context.parent.request.
{
"url": "https://docs.example.com/docs/example.pdf",
"method": "GET",
"headers": {
"accept": [
"*/*"
],
"cookie": [
"fslbs=xxxxxxxxxxxxxxxxxxxxxxxxxxxxx; cookiesession1=xxxxxxxxxxxxxxxxxxxxxxxxxxx"
],
"user-agent": [
"SitecoreSearchBot"
]
},
"body": "",
"context": {
"parent": {
"documents": [
{
"locale": "en_us",
"tag": "content",
"isLocalized": false,
"data": {
"description": "Example description",
"id": "https___docs_example_com_example",
"name": "Example Title",
"title": "Example Title"
"type": "Product",
"url": "https://www.example.com/example-page",
"bannerimage": "https://media.example.com/v1/media/edge/images/example/social/example-og.jpg?h=404&iar=0&w=632",
"body": "lorem ipsum",
"custom_attribute_category":"Category 1",
"timestamp": null,
"useragent": null
}
}
],
"request": {
"url": "https://www.example.com/example-page",
"method": "GET",
"headers": {
"accept": [
"*/*"
],
"cookie": [
"sc_site=EXAMPLE"
],
"user-agent": [
"SitecoreSearchBot"
],
},
"body": ""
},
"response": {
"headers": {
"age": [
"1507"
],
"cache-control": [
"public, max-age=0, must-revalidate"
],
"content-security-policy": [
"default-src 'self'; script-src 'self' 'unsafe-inline'"
],
"content-type": [
"text/html; charset=utf-8"
],
"date": [
"Fri, 29 Aug 2025 13:24:15 GMT"
],
"etag": [
"W/\"5anhtq95cl7p14\""
],
"server": [
"Vercel"
],
"strict-transport-security": [
"max-age=63072000"
],
"x-matched-path": [
"/en/"
],
"x-vercel-cache": [
"STALE"
],
"x-vercel-id": [
"xxxxxxxxxxxxxxxxxxxxxxx"
]
}
}
}
}
}
Let’s say a we are trying to index a PDF. Well we don’t want to treat that PDF like every other page. We can first determine it’s a PDF that is going through the Document Extractor with a simple test, as shown below. You’ll see we are using some regex to identify if the URL points to a PDF. You could use the same logic for any file type. It’s also possible to verify the information in question based upon the request header.
// If the URL ends in .pdf (case-insensitive), return a reduced detail object
if (/\.pdf($|[?#])/i.test(url)) {
return [{
'id': id,
'url': url,
'type': 'pdf',
'name': $('title').text() || $('meta[name="pdf:docinfo:title"]').attr('content') || url.split('/').pop().replace('.pdf','').replace(/[-_]/g, ' '),
'title': $('title').text() || $('meta[name="pdf:docinfo:title"]').attr('content') || url.split('/').pop().replace('.pdf','').replace(/[-_]/g, ' '),
// Apply referring page metadata
'custom_referring_title': request?.context?.parent?.documents[0]?.data?.title,
'custom_attribute_category': request?.context?.parent?.documents[0]?.data?.custom_attribute_category,
}];
}
As you’ll notice, we’re also applying some custom metadata based upon the referring page. Specifically, we’re attaching the custom_attribute_category value to the PDF. This may not be necessary, but could be quite valuable.
While you can keep the Document Extraction process simple, only getting what you need from a page. You aren’t limited to only the page in question, as we’ve shown above. We’ve only touched on what is possible and really you could build out extremely complex tagging based on the referring history of a document.

